La TDS, como es lógico, se ha utilizado profusamente en la psicología (recientemente, por ejemplo, se ha propuesto como paradigma en el estudio de percepción de contingencias: Allan, Siegel y Tangen, 2005), pero también se ha aplicado en muchos otros campos, como la inteligencia artificial y la medicina (en oftalmología tiene cierta tradición), y algunos de sus aspectos todavía están presentes en la ingeniería aplicada (las curvas ROC que se usan en el desarrollo y evaluación de los sistemas de control de calidad y que luego mencionaremos). Aunque se trata de una teoría con evidente despliegue matemático, creo que, siempre y cuando me las arregle para evitar fórmulas matemáticas y rodear ciertos argumentos técnicos, es un tema razonablemente accesible incluso para los profanos en la materia. Así que me voy a atrever a haceros esta introducción, con la que espero no ser mucho más tedioso que de costumbre.
Detectando la señal
Como en toda buena introducción, vamos a partir de un punto muy básico. Tenemos un sistema (sea natural, como una persona, o artificial, como un detector de sonidos en un dispositivo anti-robos) cuya misión es detectar un determinado estímulo, que llamaremos "señal", distinguiéndolo de cualquier otro. Vamos a suponer que la tarea consiste en reconocer un pitido de una frecuencia determinada (ej: 3000 Hz). Cada vez que el pitido de 3000 Hz sea presentado, el sistema tiene que emitir inmediatamente una respuesta, indicando que ha captado y reconocido la señal (respuesta positiva). En cualquier otro caso (es decir, cuando no ha sido presentado un pitido de 3000 Hz), el sistema ha de emitir una respuesta negativa. Este comportamiento que llevan a cabo las personas y los animales en los experimentos típicos de psicología (o en una prueba audiométrica) no es tan diferente del que realizan máquinas tan sencillas como los detectores de movimiento o los termostatos.
Sin embargo, se apresuran a apuntar desde la TDS, la detección de la señal siempre se lleva a cabo en un entorno "ruidoso". Es decir, repleto de otros estímulos (auditivos o de cualquier otro tipo), que no son la señal pero en todo caso la acompañan. De forma que, cuando se presenta la señal, realmente el sistema está captando "señal + ruido", y debe distinguir esta estimulación de la situación alternativa "sólo ruido". Esto es lo que nos ocurre a todos cuando escuchamos la televisión o la radio: creemos escuchar sólo la voz del locutor, pero realmente nuestros oídos están captando muchos otros sonidos a la vez, seamos conscientes de ellos o no (el tráfico de la calle, las voces del público, las imperfecciones de la señal de audio de la TV o radio, y las imperfecciones de nuestro propio sistema auditivo).
Evidentemente, el ruido hace más difícil la tarea de detección de la señal, provocando falsas alarmas (el sistema cree detectar la señal cuando ésta no ha sido presentada) y rechazos equivocados u omisiones (el sistema pasa por alto la presentación de la señal). En general, con respuestas binarias como ésta (es decir, el sistema sólo responde "Sí" o "No"), sólo pueden darse las siguientes cuatro situaciones:
a) Acierto (Hit): La señal estaba ahí (señal + ruido) y el sistema la detecta.
b) Falsa alarma (FA): El sistema cree detectar la señal, pero realmente sólo había ruido.
c) Fallo por omisión (Miss): La señal estaba ahí (señal + ruido) pero el sistema no la detecta (esto es, la confunde con el ruido).
d) Rechazo correcto (RC): El sistema no detecta la señal, y efectivamente sólo había ruido.
Un sistema sensible y específico minimizará el número de fallos por omisión y falsas alarmas, a la vez que mostrará un número grande de aciertos y rechazos correctos.
Demos un paso más. Vamos a fijarnos en la siguiente imagen (pero que nadie se asuste, no me detendré en aspectos técnicos):

Asumamos que las propiedades de los estímulos que constituyen el ruido (por seguir simplificando, ciñámonos a las frecuencias sonoras de nuestro ejemplo) tienen cierta variabilidad aleatoria. A veces el proceso de detección ocurre mientras se escucha de fondo una voz aguda, otras veces el experimentador puede haber empleado sonidos distractores de frecuencia grave, etc. Para haceros una idea, pensad por ejemplo en el famoso "ruido blanco", o ese sonido desagradable que se escucha cuando un receptor de radio está mal sintonizado en una frecuencia entre dos canales: el ruido general que escuchamos parece conformado por multitud de ruidos aleatorios.
Si la frecuencia del ruido es aleatoria, sus valores se distribuyen según una curva de frecuencias que en este caso sigue una ley normal. En la imagen, he representado las distribuciones normales del ruido (curva roja) y de la "señal + ruido" (curva negra), suponiendo que en el eje horizontal tenemos los distintos valores de frecuencia sonora (en Hz). Los que se hayan perdido con la alusión a "distribuciones normales" pueden consultar este enlace y luego volver al post, pero la idea es que los valores más frecuentes de una variable aleatoria son cercanos a la media de esa muestra, mientras que los valores más extremos de las distribuciones (los más alejados de la media por ambos lados) son también los menos frecuentes.
Diferenciando la señal del ruido: índice de sensibilidad
Las medias de las frecuencias del ruido y de la "señal + ruido" son diferentes (cada una está en el centro de su distribución correspondiente) y las he representado con dos líneas verticales discontinuas. Cuanto más diferentes sean esas medias, es decir, cuanto más separadas estén las "crestas" de las curvas, más sencillo será el problema de discriminar entre los dos estímulos, más fácil reconocer cuándo hemos captado "ruido" y cuándo hemos captado "señal+ruido". A la distancia que separa ambas medias la representamos mediante el parámetro d', que es el índice de discriminabilidad o de sensibilidad.
Imaginemos que el ruido tuviese una frecuencia media de 150 Hz (el equivalente a una voz masculina grave y atractiva). Eso centra la distribución del ruido en torno a este valor, donde estará la "cresta" de la curva que representa los valores del ruido. La diferencia entre la media de las frecuencias del ruido y la media de las frecuencias de la "señal + ruido" es grande (es decir, el parámetro d' tiene un valor alto: 3000-150 = 2850)(ver NOTA 1). Visualmente identificaremos esta situación porque las curvas "ruido" y "señal + ruido" estarán más separadas. Por lo tanto, no tendremos excesivos problemas en reconocer cuándo se ha presentado la señal de 3000 Hz si el entorno en el que realizamos la tarea consiste en un discurso leído por una persona con voz grave (frecuencia media = 150 Hz). Sin embargo, esto se vuelve más peliagudo si la frecuencia media del ruido es similar a la frecuencia media de la señal (es decir, si d' tiene un valor pequeño), como por ejemplo 2500 Hz (3000-2500 = 500). En este último caso las curvas se solaparían en mayor medida que en el ejemplo anterior.
Emitiendo una respuesta: ¿Estaba la señal ahí?
Bien, así que exponemos al sistema a la estimulación sonora y luego le "preguntamos": ¿Estaba la señal ahí, sí o no? El segundo componente importante en la TDS es el criterio de respuesta, identificado con el parámetro β. Este parámetro pretende representar la tendencia del sistema a sesgar su respuesta en una dirección u otra (hacia el "Sí, he captado la señal" o hacia el "No, no la he captado"). En muchos casos, la respuesta no es una función directa del índice de sensibilidad d' (es decir, de la dificultad de diferenciar ambos estímulos). Hay veces en las que estamos casi seguros de que hemos oído la señal, pero por si acaso preferimos no arriesgarnos, así que damos una respuesta negativa. Y a veces sucede justo lo contrario. En el siguiente gráfico he representado el criterio de respuesta como una línea verde vertical. Si el sistema capta un sonido cuya frecuencia está a la derecha de la línea vertical (β es positiva), tenderá a responder positivamente, y lo inverso ocurrirá si la frecuencia captada está a la izquierda del criterio.

La inclusión del criterio de respuesta en esta imagen nos deja ver 4 áreas bajo las curvas (las veis en 4 colores):
a) Acierto (Hit): Se ha presentado la señal (curva negra), y el sonido captado por el sistema (señal + ruido) está a la derecha del criterio (la línea vertical), por lo que la respuesta es positiva. El sistema detecta correctamente la señal.
b) Falsa alarma (FA): Se ha presentado un estímulo que no es la señal (ruido, curva roja), pero está a la derecha del criterio, por lo que la respuesta es positiva, y errónea.
c) Fallo por omisión (Miss): Se ha presentado la señal (curva negra), pero el sonido captado por el sistema (señal + ruido) está a la izquierda del criterio, por lo que la respuesta es negativa. Por lo tanto, el sistema no ha detectado la señal.
d) Rechazo correcto (RC): Se ha presentado un estímulo que no es la señal (ruido, curva roja), y que además está a la izquierda del criterio, por lo que la respuesta es negativa y correcta.
Lo interesante del gráfico es que, si refrescamos un poco las clases de geometría, podemos calcular las áreas bajo las curvas, de forma que es posible traducirlas a probabilidades. La probabilidad bajo la curva completa es igual a 1 . Gracias a unos cálculos sencillos en los que no me entretendré, es posible calcular las cuatro áreas de la imagen.
Esto significa, en la práctica, que cuando conocemos d' y el criterio de respuesta, podemos calcular las probabilidades (representadas como áreas) de que un sistema produzca aciertos, falsas alarmas, fallos por omisión y rechazos correctos, y de este modo predecirlos. Imaginad la utilidad de este tipo de cálculos en la fabricación y evaluación del funcionamiento de, por ejemplo, cualquier tipo de sensor o máquina detectora (de sonidos, movimiento, temperaturas...). Es aquí donde puedo introducir dos conceptos clave, la sensibilidad y la especificidad del sistema detector, y entenderlos en clave probabilística: la sensibilidad es la probabilidad de acierto sobre el total de veces que se presenta la señal; la especificidad es la probabilidad de cometer una falsa alarma sobre el total de veces que no se presenta la señal (ver NOTA 2). El sistema perfecto es sensible (detecta la señal siempre o casi siempre que aparece) y específico (es capaz de distinguir la señal del ruido y no da una respuesta positiva cuando no está la señal).
Ya en un plano psicológico, hay ciertas manipulaciones que podemos planear para alterar las probabilidades de cada tipo de situación. Una de las más obvias es el coste de respuesta. Imaginemos que, en el contexto de un experimento de TDS, proponemos a una persona un juego en el que ganará y perderá puntos según la siguiente tabla:
Aciertos: +10 puntos
Fallos por omisión: -10 puntos
Falsas alarmas: -3 puntos
Rechazos correctos: +3 puntos.
Lo que más conviene a este participante es adquirir una actitud arriesgada. Más vale dar alguna falsa alarma de vez en cuando (-3 puntos) que dejar pasar una señal y cometer un fallo por omisión (-10 puntos). Esto va a mover el criterio de respuesta (línea verde en el anterior gráfico) hacia la izquierda, alterando las probabilidades de cada tipo de suceso (aciertos, omisiones, falsas alarmas y rechazos correctos).
Curvas ROC
Por último, debo mencionar uno de los instrumentos más útiles en la TDS y en sus aplicaciones a distintos campos: las curvas ROC (Receiver Operating Characteristic). En estas curvas se confronta gráficamente la sensibilidad del sistema con su especificidad. El espacio ROC se construye mediante 2 ejes: el eje vertical representa la probabilidad de acierto (sensibilidad); el eje horizontal la probabilidad de una falsa alarma (especificidad).
Un sistema detector de señales que no ha sido entrenado correctamente mostrará un patrón de respuestas aleatorio, que se representa mediante una línea recta de 45º (mirad el gráfico en este enlace). Es decir, para ese sistema ineficiente es igual de probable producir un acierto que una falsa alarma. No es sensible ni específico. Esta línea representa la aleatoreidad de la respuesta.
Sin embargo, los sistemas suelen tener un desempeño mucho mejor que éste, y sus respuestas se representan por medio de una curva que nos da una indicación de su eficiencia: si el número de aciertos es alto y el de falsas alarmas reducido (esto es, si el sistema es muy sensible y muy específico), las respuestas van a representarse mediante una curva que va a alejarse de la línea de aleatoreidad, y por el contrario va a acercarse mucho a la esquina superior izquierda del plano. Cuanto más se acerque a este punto la curva, mayor será el área bajo dicha curva, y más eficaz es el sistema en su tarea de reconocer la señal (muchos aciertos, pocas falsas alarmas). Y podremos cuantificar esa eficacia, que es lo interesante.
Hasta aquí esta demasiado extensa (¡pero humilde!) introducción a la TDS. Espero no haber aburrido más de la cuenta. He intentado por todos los medios evitar los tecnicismos y las fórmulas matemáticas, y creo que lo he conseguido casi del todo, evitando desanimar (o eso espero) a quienes se intimiden fácilmente con las matemáticas. Quienes ya conozcan profundamente la TDS, por otro lado, quizá encontrarán en este post, sin mucho esfuerzo, inexactitudes y errores fruto de mi afán simplificador, o bien de mi desconocimiento, pues tampoco me considero un experto en la materia, ¡sólo un aficionado más! Por favor, no dudéis en utilizar los comentarios para corregirme, que para eso están ;-)
Referencias:
Allan, L. G., Siegel, S., & Tangen, J. M. (2005). A signal detection analysis of contingency data Learning & Behavior , 33 (2), 250-263.
Green, D.M., Swets J.A. (1966) Signal Detection Theory and Psychophysics. New York: Wiley.
NOTA 1: Por supuesto, estoy simplificando este ejemplo. Si la frecuencia de la señal por sí sola es 3000 Hz y la frecuencia media del ruido es 150 Hz, la frecuencia media de la suma "señal + ruido" debería de ser menor de 3000 Hz. En cualquier caso, es un detalle en principio irrelevante para mi exposición.
NOTA 2: La sensibilidad se calcula de la siguiente forma: nº de aciertos / (nº de aciertos + nº de omisiones). Por otro lado, la especificidad es: nº de rechazos correctos / (nº de rechazos correctos + nº de falsas alarmas).
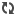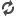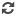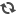 Iniciando sesión...
Iniciando sesión...









0 comentarios:
Publicar un comentario